With increasing social media incidents of election-related violence on twitter and social media, I decided to perform a quick network analysis of #ReportHate and whywereafraid (which, as of this writing, has removed its twitter link from its site). I am interested in examining the development of these online communities, if there are significant overlaps between them, and if there are opportunities for increased cooperation.
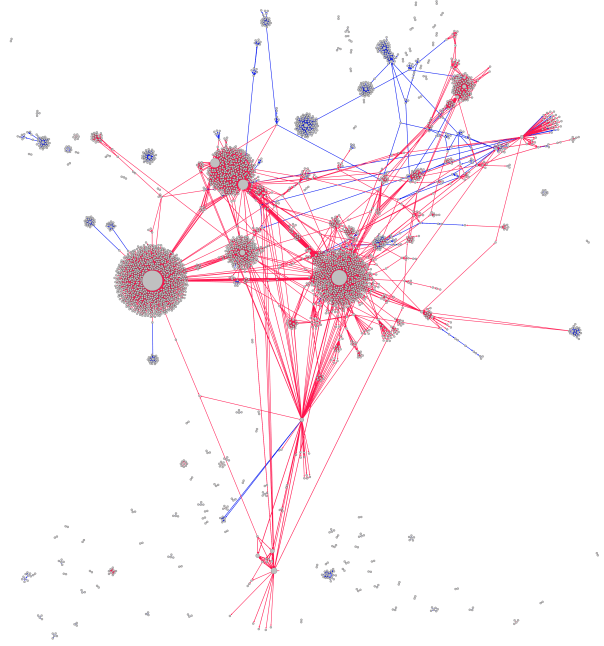
The main component of the #ReportHate network. Dr. Singh’s community is in purple, the SPLC is in green, and the alt-right grouping is in red.
First, I looked at each network in isolation. I started with the network formed around #ReportHate, which consists of 2,781 nodes, 4,217 edges and 79 components. (A quick network primer: nodes are users or hashtags, while edges represent users mentioning a hashtag or another user. Components are parts of the graph where every node can trace a path through a number of edges to another node, and degree is the number of edges connecting a node to other nodes).
Surprisingly to me, the SPLC (@SPLCENTER) is not the node with the highest degree; that honor belongs to Dr. Simran Jeet Singh (@SIKHPROF), a professor of religion at Trinity University, despite SPLC’s approximate 9-1 advantage in followers (96.3 thousand to 10.7 thousand). It will be interesting to see if this disparity closes as more individuals are aware of the hashtag.
The top ten nodes by degree are dominated by two very different philosophies. @SIKHPROF, @SPLCENTER, @SHAUNKING, @AMYWESTERVELT, @TRUMPSWORLD2016, and @THIERISTAN are certainly aligned with progressive causes and appear to be supporters of the SPLC’s efforts to accurately report hate crimes. However, the next major node on the graph, @STOPHATECRIMEZ, appears to be an alt-right account (including an emoticon frog as a stand-in for Pepe the Frog), which tweets links to accounts of violence against Trump voters (dominated by links to YouTube) and refutations of violence committed by Trump supporters. The accounts that retweeted this account likewise seem to be dominated by alt-right and far right wing individuals, and the hashtag #HATECRIME is almost exclusively used by this group.
Moving on from the alt-right component of the graph, it is apparent that there are several large clusters of SPLC supporters that as of yet do not have much interconnectivity. As this is a relatively new hashtag, I expect a growth of connections between clusters; if not, there is is an opportunity for the “central” nodes of each cluster to reach out to each other and establish a more robust online community. Another potential issue are nodes that are otherwise disconnected from the network; if these individuals are tweeting about incidents, it would be beneficial to reach out (virtually) and bring them into the larger #ReportHate network.
Unlike the #ReportHate network, with a strong connected component, the whywereafraid network is far more dispersed and much smaller. There are 992 nodes and 938 edges, with 151 components. The node with the highest degree count is Patrick Kingsley (@PATRICKKINGSLEY), a foreign correspondent with the Guardian paper; his high degree is the result of his tweet linking to the whywereafraid tumblr account.
The whywereafraid network
The other two of the top three nodes, @ADAMPOWERS and @JAMIETWORKOWSKI, seem to be allied with the progressive movement. The next node with the highest degree is the official account of Donald Trump (@REALDONALDTRUMP). However, this is due to other twitter users castigating him over election violence.
I then placed the networks together, to see if there was any overlap between the two growing communities. There are 26 users and 19 hashtags in common; when the entire network is placed in a graph, the node with the node with the highest degree of the 26 is @SHAUNKING, who is mentioned four times by other uses to bring his attention to whywereafraid. There are other tentative connections, but for the most part the two networks are very distinct, with little cross conversation.
The combined network. Edges that are from the #ReportHate data are in red, edges from the whywereafraid data are in blue.
This represents a danger and an opportunity for the supporters of #ReportHate and whywereafraid. As the #ReportHate and whyweareafraid networks grow, there are likely to have increased links due to shared common interests, but there is the real possibility that many users will remain tied to their initial choice of hashtag, and not participate in the wider community or conversation. If nodes that are structurally important (a high betweenness centrality) in the #ReportHate graph, such as @SIKHPROF and @AMYWESTERVELT, could be brought into conversation with the major nodes of the whyweareafraid graph, then there is a good chance to merge the two networks, increasing awareness, mutual support, and an increased online presence.
The approximately 1,172 mile Dakota Access Pipeline1 has been highly controversial since its public unveiling in 2014.2 The Standing Rock Sioux and allied organizations took ultimately unsuccessful legal action to stop construction of the project, 3 while youth from the reservation began a social media campaign which gradually morphed into a larger movement with dozens of associated hashtags.4I performed network analysis on #NODAPL, the most prominent of these hashtags on Twitter, between October 22 – 30, 2016. This revealed some interesting trends in the data, including the key role of alternative media, celebrities, and seemingly random twitter users holding the network together. Another surprising finding was the relatively minor role that republican candidate Donald Trump’s twitter account plays in the #NODAPL conversation, especially compared to the accounts of Barack Obama, Hilary Clinton, Bernie Sanders, and Dr. Jill Stein.
My Visualization of the #NODAPL network
Preliminary Network Analysis:
Due to restrictions from the Twitter API and crashes / limitations from the software (see below), I do not have complete access to all Tweet traffic involving #NODAPL.5 I used the Twitter Archiving Google Sheet (TAGS) 6.16 to capture tweets that featured #NODAPL somewhere the tweet text. The resulting sheets were then imported into a database, then exported into an edges table for use in Gephi. For technical details, see the “Detailed Procedure” section below.
Basic to any network analysis is the concept of nodes and edges. Nodes can represent people, places, things, ideas, etc – they are entities on the graph. In this case, nodes are twitter users and hashtags. Edges associate nodes in some manner; they can represent friendship, biological relationships, enmity, or anything else that links two nodes. For my analysis, edges are anytime a user includes a user name or hashtag in a tweet. For example, one of the most prominent users in this study, @RUTHHHOPKINS is represented as a node, with an edge created to the node #NODAPL every time she uses the hashtag in a tweet, like the example below:
# NODAPL itself was excluded as a node in this analysis, as every tweet and user would be directly connected to it. This network features 133,702 nodes linked by 630,393 edges.7I used Gephi to identify communities of nodes that are strongly linked together, which are represented by different colors in the network visualization.8 In addition, I ran some basic network statistics, including measuring the degree of nodes (the number of edges between two individuals, hashtags, or individuals and hashtags) on the graph. In these measurements out-degree indicates that a node initiates a link to another node in the graph, which in this case means another user name or hashtag was mentioned in a text by the node in question. in-degree measures incoming edges, which indicates that a particular node is the subject of a twitter conversation.
I first looked at the in-degree measurement. #STANDINGROCK was by far the node with the highest in-degree, indicating its popularity as a potential alternative hashtag to #NODAPL. @POTUS, the official twitter account of the President of the United States, was in second place, followed by #WATERISLIFE, @HILLARYCLINTON, @OFFICIALJADEN, @UR_NINJA, @SHAILENEWOODLEY, @MARKRUFFALO, and @RUTHHHOPKINS. In this list, only two nodes are not politicians, hashtags, or celebrities. @UR_Ninja is the official twitter account of Unicorn Riot9, a 501(c)3 nonprofit organization based in Minneapolis, Minnesota10 which has done extensive reporting on the Dakota Access Pipeline protests. @RUTHHHOPKINS is the twitter account of Ruth Hopkins, a Dakota/Lakota Sioux writer, journalist, and blogger. The high degree count on these nodes indicates that they may function as an information service, where their reporting on the situation is retweeted and mentioned by many other nodes in the network.
This measurement also revealed a marked difference between the in-degree and out-degree of nodes. The top 34 nodes by number of degrees are so dominated by in-degree connections that no node has an out-degree that contains more than 3.17% of its total edges. This reveals that such nodes are being “talked at”: they are mentioned in tweets, retweeted in large numbers, but by and large feature extremely limited further engagement with other Twitter users.
A particular user group is indicative of this trend. Few politicians have used Twitter to actively engage with activists or to contribute to the dialogue surrounding the #NoDAPL movement. In some cases this is not surprising; the official twitter account of the President of the United States can scarcely be expected to contribute extensively to dialogue on twitter. Despite being the seventh highest degree node and an occupation of her Brooklyn campaign headquarters on October 27, 201611 @HILLARYCLINTON, the official account of Hillary Clinton, has likewise not responded to #NoDAPL conversations on twitter. The official account of Bernie Sanders, @SENSANDERS, has also not extensively engaged with #NODAPL. However, on October 31, 2016, which is outside of the bounds of my data set, his account did issue a series of tweets in support of the # NODAPL movement.12
There are many reasons the Dakota Access Pipeline should be stopped. I want to call attention to a few of the biggest. #NoDAPL
Another account of a politician, Dr. Jill Stein (@DRJILLSTEIN), is twelfth on in-degree, but only has five outwardly directed edges. Despite active involvement at the protests leading to charges of criminal trespass and criminal mischief,13 Dr. Stein’s twitter account has barely engaged with other users, with the only mentions in this data set originating from a retweet that mentioned Hillary Clinton and Barack Obama.14Interestingly, despite over 1,000 retweets (many of which were collected by this study), her tweet mentioning both Hillary Clinton and Donald Trump15 was not captured by the TAGS software.
Perhaps surprisingly for a major party candidate, the twitter handle of Donald Trump, @REALDONALDTRUMP, is an outlier on this list: he ranks at 112,160 with only 933 total mentions. Trump’s publicized investments and connections with the Dakota Access project16 and environmental positions, including discounting climate change,17 almost certainly makes him unlikely to be sympathetic, let alone an ally of the # NODAPL movement. Indeed, most of his mentions on the network are simply retweets of Dr. Jill Stein’s criticism against Donald Trump and Hillary Clinton’s lack of involvement in the pipeline issue.18
Drilling down further into the data, I next looked at the nodes with the highest out-degree, which represents nodes who mentioned other users and hashtags. There were some interesting variations from the trends of in-degree nodes. Three users, @DEANLEH, @CANATIVEOBT, and @WMN4SRVL had in-degree and out-degree measurements that were no more than 20% divergent from each other. However, this does not mean that these nodes are engaged in extensive online conversations. These accounts all feature extensive retweets and linkages to different causes often associated with the progressive movement, including climate change awareness, opposition to institutional racism, feminism, and anti-corporatism. All three of these accounts seem to perform a function similar to news aggregation, as the majority of their mentions are retweets from other sources and are not extensive discussions with other users.
Another useful statistics, betweenness, measures the number of shortest paths (connections between any two nodes on the graph that may involve any number of additional nodes) that pass through a specific node.19 Nodes with a high betweenness are “central” in that they play a critical role in connecting (and therefore moving information) through the network. The single node with the highest betweenness is @UR_NINJA, which combined with its high degree ranking, suggests that the news service plays a critical role in bringing together individuals on the graph who are interested in social justice / progressive issues. Four other nodes in the top 25 betweenness list are likewise in the top 25 nodes by degree.
The remaing nodes are somewhat surprising. The twitter profile for second highest betweenness node, @TNPMR has a limited online footprint outside of Twitter, and does not seem to be involved in a leadership capacity in a social movement or media organization. Another important node in this measurement, @AMAZONMILLER, only scores 1638th in total degrees, yet still retains an important place in the network structure. Looking further at this data, I next examined at each individual user’s Twitter profile who scored in the top 25 for betweenness. I divided this list into people who seem to be primarily interested in progressive causes in general vs. those who expressed affinity for indigenous rights issues. The results were nearly evenly split, with a slight edge to the more general progressivists. However, only two of top ten nodes in the betweenness category focused primarily on indigenous issues, while the rest were concerned with progressivist issues more broadly. What this may indicate is that, as a whole, indigenous activists may face future difficulties in promoting their narrative outside of the more general progressive interests of the online community.
Further Observations:
These preliminary steps have also revealed some issues about data collection and curation. Twitter’s REST and streaming APIs are woefully inadequate for examining the whole data set. While Twitter provides, in theory, a representative sample of the data set, one of the powers of social network analysis is the discovery of weak ties and other network structures which are by definition not representative of the network as a whole. This can be frustrating for academic study of the network, and extremely detrimental to movements that depend on social media to transmit their messages. Groups can look at their own twitter histories, but the larger network structure, along with crucial weak ties, may be invisible to them.
Although Twitter does provide mechanisms for obtaining the entire history of hashtag usage, the organic development of other hashtags which are not heavily watched from the beginning is almost certainly a cost-prohibitive proposition for social movements that are loosely organized, under-funded, and / or have limited computer infrastructure. It would be a significant benefit for such groups to gain access to the Twitter history of their movements, and be able to the evolution of the conversation on social media. As hashtag use can grow organically, with many different signifiers used for conversations, Twitter’s current pricing structure and data access model puts these groups at a severe disadvantage and hinders the identification and cultivation of allied communities and supporters.
A less pressing, but nevertheless important, issue is access to Twitter’s archive by researchers. Unlike print material or traditional media, which may be tedious to analyze but are fully (and for the most part cheaply) accessible to interested parties, the complete set of tweets on a topic are impossible to study without significant funding. Even if a researcher could guess all of the hashtags that could emerge from a dynamic topic, the Twitter streaming API does not provide all relevant tweets. Such limitations make it challenging to use Twitter data in a pedagogical setting. Some of my students have expressed interest in conducting similar projects, but the need for constant downstream connections and the high cost of historical tweets have made all but the most superficial studies impossible. There needs to be a more cost-effective means for projects operating on a limited budget, students, and other academic uses of Twitter’s data.
Next Steps:
In addition to the data set on #NoDAPL featured here, I have also compiled a number of hashtags and data in separate TAGS sheets which can be combined to see more of the network. I am currently running a python script to grab more tweet data from the streaming API, which should provide more tweets. After placing this data in the network and performing some basic sentiment analysis, I want to see if distinct communities have formed around different hashtags, and if those communities have noticeably different rhetorical strategies that correspond to the inclusion of certain hashtags. A long term goal is to secure funding to obtain the complete twitter archive of #NODAPL and related hashtags in order to perform a full social network and sentiment analysis. In addition, I would like to examine the twitter history of @UR_Ninja and other alternative news organizations to see if their followers form recognizable activist communities. As part of this analysis, I am especially interested to see how these communities change when news organization shifts their focus between causes (like #FERGUSON to #NODAPL), and to examine the interactions of these virtual communities with different social movements.
To overcome the issues I discovered with TAGS and TwitterStreamingImporter, I am currently running a python script (modeled after http://adilmoujahid.com/posts/2014/07/twitter-analytics/) that pulls in the full json object from Twitter’s streaming API for a number of hashtags related to #NODAPL. I think the best approach is to perform a weekly update of a “master” network that captures all of the data that I can dealing with #NODAPL, and then running statistics / etc from a filtered network in Gephi. I will be sure to post any additional developments here.
Detailed Procedure:
The first difficulty in analyzing Twitter traffic is actually obtaining Twitter data. While Twitter does retain a historical archive of all tweets, this resource is currently inaccessible for academic research unless licensing fees are paid to an archival service such as GNIP. There is an indication that GNIP is aware of the power of Twitter analytics for academic research, and there are different pricing plans available,20 but as my project is currently in the exploratory phase, I am operating without any funding. As such, I needed an alternative.
I first used TAGS to pull historical and incoming tweets into separate google sheets for each hashtag I was interested in. TAGS uses Twitter’s REST API, which limits search rates and results.21 I ran into rate limits rather quickly with my searches; in addition, my documents in google also hit their size and row limit. TAGS does not provide the entire result from the Twitter API: fields like place, retweeted (which indicates if a tweet was retweeted or not), and other useful fields are left off. Finally, I noticed that the text of tweets was often truncated; this made searching form complete user names, hashtags, and full text problematic. Although TAGS is a convent way to collect tweets, it can not possibly hope to represent the full network.
Despite these imitations, TAGS can still provide some powerful insights with a little modification. After importing my TAGS documents into a postgresql database, I mined the tweet text for all user mentions and hashtags from individual twitter users, which formed the edges of my network. I then imported this into Gephi v.0.9.122, where I performed some basic network analysis and visualizations of the data.
After this analysis, I decided that I needed to capture more tweets as they are issued. I used the TwitterStreamingImporter plugin for Gephi,23 which uses Twitter’s streaming API.24 The result is not all tweets that contain specified search terms, but is instead a representative sample that numbers up to 1% of global tweets. At ~ 300 -500 million tweets per day,25 the streaming api will return 3 – 5 million tweets on a given subject. For small data sets this may be sufficient, but it is impossible to tell how truly representative this sample is without the complete Twitter firehose.26
Unlike TAGS, TwitterStreamingImporter requires a constant internet connection to compile tweets. This is impracticable if not impossible for individuals who use a single laptop or other machine between different locations. I also experienced some crashes while performing analytics and changing/ running the visualization layouts; anyone wishing to style twitter data using this technique may wish to save constantly and export different files for styling purposes. This plugin does a nice job of drawing edges between users, tweets, and hashtags, and specifies the type of edge (tweet, retweet, hashtag, etc), although I would still like some more detailed information. The code is freely accessible,27 so I may be able to fork the repository and create a new plugin that pulls in all the data that I am interested in (especially geolocations, time of the tweet, etc). However, I think simply using a python script on a persistent connection will be my next step in this analysis.
Notes:
1LLC Dakota Access and United States Army Corps of Engineers, “Environmental Assessment: Dakota Access Pipeline Project, Crossings of Flowage Easements and Federal Lands” (U.S. Army Corps of Engineers, Omaha District, 2016), 8,http://purl.fdlp.gov/GPO/gpo74064.
7I used Gephi with the OpenOrd Layout to create the network visualization1 after modifying TAGS data in a postgresql database. Although the OpenOrd layout is intended for undirected graphs (seehttps://marketplace.gephi.org/plugin/openord-layout/), its ability to handle large datasets and limited computing resources made it an attractive choice for this investigation.
8The modularity for the graph is 0.414, with 862 communities detected. 32 of these communities had 100 or more nodes, and totaled 131,080 of the 133,702 total, which is 98.04% of the total.
26Research on the representative accuracy of Twitter’s API has been mixed; see Fred Morstatter et al., “Is the Sample Good Enough? Comparing Data from Twitter’s Streaming API with Twitter’s Firehose,” arXiv Preprint arXiv:1306.5204, 2013; Fred Morstatter, Jürgen Pfeffer, and Huan Liu, “When Is It Biased?: Assessing the Representativeness of Twitter’s Streaming API,” in Proceedings of the 23rd International Conference on World Wide Web (New York, NY: ACM, 2014).
Dakota Access, LLC, and United States Army Corps of Engineers. “Environmental Assessment: Dakota Access Pipeline Project, Crossings of Flowage Easements and Federal Lands.” U.S. Army Corps of Engineers, Omaha District, 2016. http://purl.fdlp.gov/GPO/gpo74064.
Morstatter, Fred, Jürgen Pfeffer, and Huan Liu. “When Is It Biased?: Assessing the Representativeness of Twitter’s Streaming API.” In Proceedings of the 23rd International Conference on World Wide Web. New York, NY: ACM, 2014.
Morstatter, Fred, Jürgen Pfeffer, Huan Liu, and Kathleen M Carley. “Is the Sample Good Enough? Comparing Data from Twitter’s Streaming API with Twitter’s Firehose.” arXiv Preprint arXiv:1306.5204, 2013.
Image from https://gephi.org/images/screenshots/layout2.png
This semester I designed a class, Introduction to Social Networks and Conspiracy Theories, that makes extensive use of Gephi along with the downloadable version of Networks, Crowds, and Markets: Reasoning About a Highly Connected World by David Easley and Jon Kleinberg. Readings on real conspiracies and conspiracy theories were compiled by myself into a course packet, and cover Ancient Athens, the assassination of Philip II, Knights Templar, the Gunpowder plot, the French Revolution, and conspiracy theories in the United States from the revolution to the present. In short, this class uses social network analysis to study paranoia from Plato to NATO.
Key to this class is the understanding and use of SNA software. I chose Gephi as it has a forgiving learning curve for creating networks and conducting basic analysis, and its cross platform capabilities were required as I do not have access to a computer lab for the class. The other deciding factor was the ease of exporting Gephi files (through the use of the excellent Sigmajs exporter) to the web, as the students will produce a number of publicly available network visualizations, in addition to a written report, for their final project.
Gephi has shown its usefulness to the class. The ability to very quickly take .csv files and make meaningful network diagrams impressed the students, and showing network filtering in real-time is a powerful way to show conceptually how eliminating bridges and key nodes can throw a network into confusion. Some other positive points:
Gephi’s GUI vs. command line tools
For my students, using a GUI has been a far better choice than a command-line or text driven interface. While the Gephi GUI can sometimes do strange things (like eliminate buttons or workspaces), on the whole its basic functionality is relatively intuitive. After a few demonstrations in the basics, the students have grasped how to create a network from spreadsheet data.
Real-time rendering
Keeping the various layouts running while filtering / changing elements of the network (especially the stand-by force atlas) powerfully illustrates many network concepts. It is also a very cheap (in time and effort!) method to create animated networks for the class.
Ease of stats
While some of the statistics I would like to see are not in the core of Gephi, the ones that are present are excellent. The students, after learning about the math and logic behind various network statistics, were quite relieved to discover how quickly Gephi can compute centrality, density, and degree measurements.
Styling
After spending some time going over the interface, the ease of selecting different attributes and measurements for node styling is something that really captured the student’s attention. I anticipate a flood of very interesting network diagrams for their final projects based on different styling / visualization choices, which is an excellent way for students to support their arguments.
Creating diagrams for the course
Using Gephi to create network diagrams for the conspiracy portion of the course is a very straightforward process, and the excellent export capabilities ensure that all of the networks I share look very professional.
While Gephi is an excellent piece of software, extensive use in the classroom has revealed some issues and missing features that do present a source of frustration for the class.
Java can be difficult
Supporting multiple operating systems with different Java installs on student laptops is an exercise in frustration. A class that uses Gephi extensively MUST have a supported computer lab, at the very least so that Java problems can be addressed and fixed for everyone at the same time in the same way. I am running my course without this, and I can attest that much class time has been wasted trying to troubleshoot Java and install issues on different OS / JVM combinations.
Gephi is not very fault tolerant
Data, at least in the humanities, is often messy, malformed, and non standards-compliant. I was stymied in class due to one character causing an issue in a data set that we found online – while text programs and Excel / OpenOffice handled the file gracefully, it blew up on Gephi.
Many of the concepts discussed in SNA texts can not be easily seen in Gephi
Concepts like triadic closure are somewhat difficult to capture, but there is nothing in Gephi to identify triads. It can compute the total number, but this is less useful for showing students where the triads are in a graph. I could also not find a way to view cliques, or to identify bridges programatically. Network balance is also something that is not readily apparent in Gephi.
Filtering can be difficult
While there are some powerful filtering features in Gephi, the class has had a difficult time conceptualizing their use and using them to their full potential. A more intuitive interface may solve some of these problems.
Some features are Broken
Embeddedness is not a core feature for Gephi, and the plugin that computes this is incompatible with the current version of the code. In addition, filtering on partition for edges does not seem to currently work – this makes identification of cliques and balanced graphs more difficult. Along with this, Gephi can be very unstable at times, and some workarounds (like exporting a newly created graph and re-importing it to ensure compatibility with multiple edges) can be a hassle.
Summary
In short, I think Gephi is a good choice for the classroom, but one that will require some serious work from the instructor. I would HIGHLY recommend that you teach Gephi in a classroom setting, where JVM and OS choices are restricted and supported by IT staff. I would like to see more educators using Gephi so we can pressure the developers (or encourage interested students!) to add more functionality to the core of the software.







You must be logged in to post a comment.